Setting up a single-session LFADS run¶
Assuming you have finished adapting the LFADS run manager classes to your dataset, you should be all set to generate some LFADS runs and start training. We’ll be setting up a drive script that will do the work of creating the appropriate instances, pointing at the datasets, creating the runs, and telling LFADS Run Manager to generate the files needed for LFADS. Below, we’ll refer to the package name as LorenzExperiment, but you should substitute this with your package name.
Follow along with LorenzExperiment.drive_script
A complete drive script is available as a starting point in +LorenzExperiment/drive_script.m for you to copy/paste from.
Lorenz attractor example¶
For this demo, we’ll generate a few datasets of synthetic spiking data generated by a Lorenz attractor using the following code:
datasetPath = '~/lorenz_example/datasets'; LFADS.Utils.generateDemoDatasets(datasetPath, 'nDatasets', 3);
This will simulate a chaotic 3 dimensional Lorenz attractor as the underlying dynamical system, initialized from 65 initial conditions. Here is a subset of 10 conditions’ trajectories:

From these 3 dimensions, we generate random matrices along which to project these 3 dimensions to produce the firing rates of individual units (plus a constant bias term). The initial conditions (defining the conditions) and subsequent dynamical trajectories are the same across datasets. Each dataset will contain a variable number of neurons (between 25–35). The rates of these neurons are then constructed by projecting the 3-d Lorenz trajectory through a dataset-specific readout matrix, adding the bias, and exponentiating. We then draw spikes from the inhomogenous Poisson process for 20-30 trials for each condition.
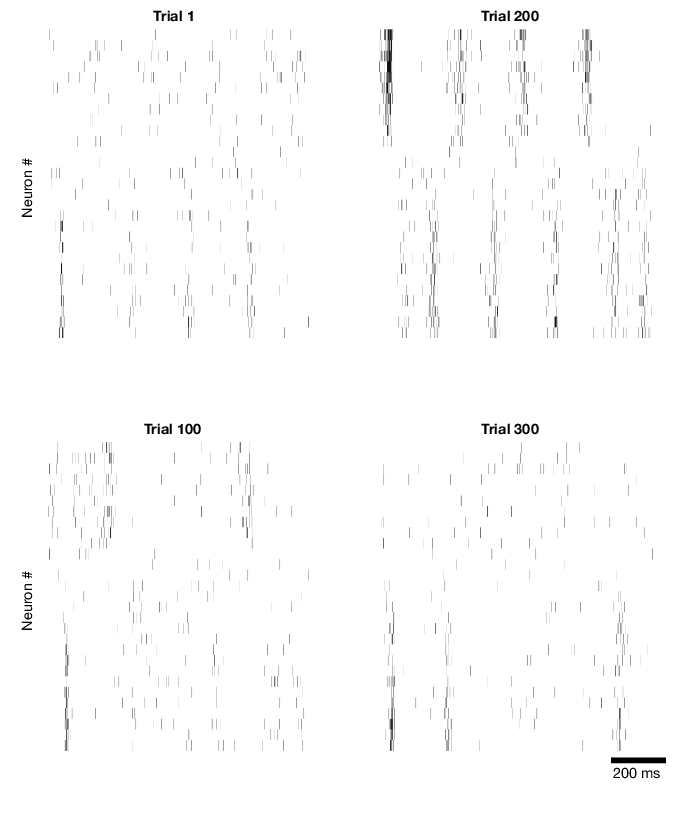
Here are a few examples of single trial spike rasters. The units have been sorted according to their loading onto the first dimension of the attractor:
Building a dataset collection and adding datasets¶
First, create a dataset collection that points to a folder on disk where datasets are stored:
dataPath = '~/lorenz_example/datasets'; dc = LorenzExperiment.DatasetCollection(dataPath); dc.name = 'lorenz_example';
Then, we can add the individual datasets within based on their individual paths. Note that when a new dataset instance is created, it is automatically added to the DatasetCollection and will replace any dataset that has the same name if present.
LorenzExperiment.Dataset(dc, 'dataset001.mat');
You can verify that the datasets have been added to the collection:
>> dc LorenzExperiment.DatasetCollection "lorenz_example" 1 datasets in ~/lorenz_example/datasets [ 1] LorenzExperiment.Dataset "dataset001" name: 'lorenz_example' comment: '' path: '~/lorenz_example/datasetss' datasets: [1x1 LorenzExperiment.Dataset] nDatasets: 1
You can access individual datasets using dc.datasets(1) or by name with dc.matchDatasetsByName('dataset001').
You can then load all of the metadata for the datasets using:
dc.loadInfo();
How this metadata is determined for each dataset may be customized as described in Interfacing with your Datasets. You can view a summary of the metadata using:
>> dc.getDatasetInfoTable subject date saveTags nTrials nChannels ________________ ______________________ ________ _______ _________ dataset001 'lorenz_example' [31-Jan-2018 00:00:00] '1' 1820 35
Create a RunCollection¶
We’ll now setup a RunCollection that will contain all of the LFADS runs we’ll be training. Inside this folder will be stored all of the processed data and LFADS output, nicely organized within subfolders.
runRoot = '~/lorenz_example/runs'; rc = LorenzExperiment.RunCollection(runRoot, 'exampleSingleRun', dc); % replace with approximate date script authored as YYYYMMDD % to ensure forwards compatibility rc.version = 20180131;
Versioning and backwards compatibility
You can optionally set rc.version just after creating the RunCollection. Version should be set to the date the script was first used to generate the LFADS files on disk, in the format YYYYMMDD. Specifying this here allows for backwards compatibility in case we need to change aspects of where LFADS Run Manager organizes files on disk or how the RunParams hashes are generated. The default rc.version will be updated if significant changes are made in the code, so manually specifying it in the drive script can be useful to “freeze” the LFADS Run Manager logic for this specific collection of runs.
Specify the hyperparameters in RunParams¶
We’ll next specify a single set of hyperparameters to begin with. Since this is a simple dataset, we’ll reduce the size of the generator network to 64 and reduce the number of factors to 8.
par = LorenzExperiment.RunParams; par.name = 'first_attempt'; % completely optional par.spikeBinMs = 2; % rebin the data at 2 ms par.c_co_dim = 0; % no controller --> no inputs to generator par.c_batch_size = 150; % must be < 1/5 of the min trial count par.c_factors_dim = 8; % and manually set it for multisession stitched models par.c_gen_dim = 64; % number of units in generator RNN par.c_ic_enc_dim = 64; % number of units in encoder RNN par.c_learning_rate_stop = 1e-3; % we can stop training early for the demo
Setting batch size
The number of trials in your smallest dataset determines the largest batch size you can pick. If trainToTestRatio is 4 (the default), then you will need at least 4+1 = 5 times as many trials in every dataset as c_batch_size. If you choose a batch size which is too large, LFADS Run Manager will generate an error to alert you.
We then add this RunParams to the RunCollection:
rc.addParams(par);
You can access the parameter settings added to rc using rc.params, which will be an array of RunParams instances.
The RunParams class will display all of the settings in an organized manner, as well as a summary of those values that differ from their defaults at the top:
>> par par = LorenzExperiment.RunParams param_YOs74u data_4MaTKO "first_attempt" c_learning_rate_stop=0.001 c_batch_size=150 c_co_dim=0 c_ic_enc_dim=64 c_gen_dim=64 c_factors_dim=8 Computed hashes paramHash: 'YOs74u' paramHashString: 'param_YOs74u' dataHash: '4MaTKO' dataHashString: 'data_4MaTKO' Run Manager logistics and data processing name: 'first_attempt' version: 20171107 spikeBinMs: 2 TensorFlow Logistics c_allow_gpu_growth: 1 c_max_ckpt_to_keep: 5 c_max_ckpt_to_keep_lve: 5 c_device: '/gpu:0' Optimization c_learning_rate_init: 0.0100 c_learning_rate_decay_factor: 0.9800 c_learning_rate_n_to_compare: 6 c_learning_rate_stop: 1.0000e-03 c_max_grad_norm: 200 trainToTestRatio: 4 c_batch_size: 150 c_cell_clip_value: 5 Overfitting c_temporal_spike_jitter_width: 0 c_keep_prob: 0.9500 c_l2_gen_scale: 500 c_l2_con_scale: 500 c_co_mean_corr_scale: 0 Underfitting c_kl_ic_weight: 1 c_kl_co_weight: 1 c_kl_start_step: 0 c_kl_increase_steps: 900 c_l2_start_step: 0 c_l2_increase_steps: 900 scaleIncreaseStepsWithDatasets: 1 External inputs c_ext_input_dim: 0 c_inject_ext_input_to_gen: 0 Controller and inferred inputs c_co_dim: 0 c_prior_ar_atau: 10 c_do_train_prior_ar_atau: 1 c_prior_ar_nvar: 0.1000 c_do_train_prior_ar_nvar: 1 c_do_causal_controller: 0 c_do_feed_factors_to_controller: 1 c_feedback_factors_or_rates: 'factors' c_controller_input_lag: 1 c_ci_enc_dim: 128 c_con_dim: 128 c_co_prior_var_scale: 0.1000 Encoder and initial conditions for generator c_num_steps_for_gen_ic: 4294967295 c_ic_dim: 64 c_ic_enc_dim: 64 c_ic_prior_var_min: 0.1000 c_ic_prior_var_scale: 0.1000 c_ic_prior_var_max: 0.1000 c_ic_post_var_min: 1.0000e-04 Generator network, factors, rates c_cell_weight_scale: 1 c_gen_dim: 64 c_gen_cell_input_weight_scale: 1 c_gen_cell_rec_weight_scale: 1 c_factors_dim: 8 c_output_dist: 'poisson' Stitching multi-session models c_do_train_readin: 1 useAlignmentMatrix: 0 useSingleDatasetAlignmentMatrix: 0 Posterior sampling posterior_mean_kind: 'posterior_sample_and_average' num_samples_posterior: 512
RunParams data and param hashes¶
If we look at the printed representation of the RunParams instance, we see two hash values:
>> par par = LorenzExperiment.RunParams param_YOs74u data_4MaTKO c_factors_dim=8 c_ic_enc_dim=64 c_gen_dim=64 c_co_dim=0 c_batch_size=150 c_learning_rate_stop=0.001 ...
These six digit alphanumeric hash values are used to uniquely and concisely identify the runs so that they can be conveniently located on disk in a predictable fashion. The first is the “param” hash of the whole collection of parameter settings which differ from their defaults, which is prefixed with param_. The second is a hash of only those parameter settings that affect the input data used by LFADS, prefixed by data_. We use two separate hashes here to save space on disk; many parameters like c_co_dim only affect LFADS internally, but the input data is the same. Consequently, generating a large sweep of parameters like c_co_dim would otherwise require many copies of identical data to be saved on disk. Instead, we store the data in folders according to the data_ hash and symlink copies for each run. If you add additional parameters that do not affect the data used by LFADS, you should specify them in your RunParams class as described here.
Below the hash values are the set of properties whose values differ from their specified defaults (as specified next to the property in the class definition). Properties which are equal to their default values are not included in the hash calculation. This allows you to add new properties to your RunParams class without altering the computed hashes for older runs. See this warning note for more details.
RunParams is a value class
Unlike all of the other classes, RunParams is not a handle but a value class, which acts similarly to a struct in that it is passed by value. This means that after adding the RunParams instance par to the RunCollection, we can modify par and then add it again to define a second set of parameters, like this:
par.c_gen_dim = 96; rc.addParams(par); par.c_gen_dim = 128; rc.addParams(par);
Generating hyperparameter value sweeps
If you wish to sweep a specific property or set of properties, you can create a RunParams instance, set the other properties as needed, and then call generateSweep to build an array of RunParams instances:
parSet = par.generateSweep('c_gen_dim', [32 64 96 128]); rc.addParams(parSet);
Or along multiple parameters in a grid:
parSet = par.generateSweep('c_gen_dim', [32 64 96 128], 'c_co_dim', 0:2:4); rc.addParams(parSet);
Specify the RunSpec¶
Recall that RunSpec instances specify which datasets are included in a specific run. For this example, we’ve only included a single dataset, so we don’t have any choices to make. We’ll run LFADS on first dataset by itself:
ds_index = 1; runSpecName = dc.datasets(ds_index).getSingleRunName(); % generates a simple run name from this datasets name runSpec = LorenzExperiment.RunSpec(runSpecName, dc, ds_index); rc.addRunSpec(runSpec);
You can adjust the arguments to the constructor of LorenzExperiment.RunSpec, but in the example provided the inputs define:
- the unique name of the run. Here we use
getSingleRunName, a convenience method ofDatasetthat generates a name likesingle_datasetName. - the
DatasetCollectionfrom which datasets will be retrieved - the indices or names of datasets (as a string or cell array of strings) to include
Check the RunCollection¶
The RunCollection will now display information about the parameter settings and run specifications that have been added. Here there is only one parameter setting by one run specification, so we’re only performing 1 run total.
>> rc LorenzExperiment.RunCollection "exampleSingleSession" (1 runs total) Dataset Collection "lorenz_example" (1 datasets) in ~/lorenz_example/datasets Path: ~/lorenz_example/runs/exampleSingleSession 1 parameter settings [1 param_YOs74u data_4MaTKO] LorenzExperiment.RunParams "first_attempt" c_factors_dim=8 c_ic_enc_dim=64 c_gen_dim=64 c_co_dim=0 c_batch_size=150 c_learning_rate_stop=0.001 1 run specifications [ 1] LorenzExperiment.RunSpec "single_dataset001" (1 datasets) name: 'exampleSingleSession' comment: '' rootPath: '~/lorenz_example/runs' version: 20180131 datasetCollection: [1x1 LorenzExperiment.DatasetCollection] runs: [1x1 LorenzExperiment.Run] params: [1x1 LorenzExperiment.RunParams] runSpecs: [1x1 LorenzExperiment.RunSpec] nParams: 1 nRunSpecs: 1 nRunsTotal: 1 nDatasets: 1 datasetNames: {'dataset001'} path: '~/lorenz_example/runs/exampleSingleSession' pathsCommonDataForParams: {'~/lorenz_example/runs/exampleSingleSession/data_4MaTKO'} pathsForParams: {'~/lorenz_example/runs/exampleSingleSession/param_YOs74u'} fileShellScriptTensorboard: '~/lorenz_example/runs/exampleSingleSession/launch_tensorboard.sh' fileSummaryText: '~/lorenz_example/runs/exampleSingleSession/summary.txt' fileShellScriptRunQueue: '~/lorenz_example/runs/exampleSingleSession/run_lfadsqueue.py'
Prepare for LFADS¶
Now that you’ve set up your run collection with all of your runs, you can run the following to generate the files needed for running LFADS.
rc.prepareForLFADS();
This will generate files for all runs. If you decide to add new runs, by adding additional run specifications or parameters, you can simply call prepareForLFADS again. Existing files won’t be overwritten unless you call rc.prepareForLFADS(true).
After running prepareForLFADS, the run manager will create the following files on disk under rc.path:
~/lorenz_example/runs/exampleSingleSession ├── data_4MaTKO │ └── single_dataset001 │ ├── inputInfo_dataset001.mat │ └── lfads_dataset001.h5 ├── param_YOs74u │ └── single_dataset001 │ └── lfadsInput │ ├── inputInfo_dataset001.mat -> ../../../data_4MaTKO/single_dataset001/inputInfo_dataset001.mat │ └── lfads_dataset001.h5 -> ../../../data_4MaTKO/single_dataset001/lfads_dataset001.h5 └── summary.txt
The organization of these files on disk is discussed in more detail here. Also, a summary.txt file will be generated which can be useful for identifying all of the runs and their locations on disk. You can also generate this text from within Matlab by calling rc.generateSummaryText().
LorenzExperiment.RunCollection "exampleSingleSession" (1 runs total) Path: ~/lorenz_example/runs/exampleSingleSession Dataset Collection "lorenz_example" (1 datasets) in ~/lorenz_example/datasets ------------------------ 1 Run Specifications: [runSpec 1] LorenzExperiment.RunSpec "single_dataset001" (1 datasets) [ds 1] LorenzExperiment.Dataset "dataset001" ------------------------ 1 Parameter Settings: [1 param_YOs74u data_4MaTKO] LorenzExperiment.RunParams "first_attempt" c_learning_rate_stop=0.001 c_batch_size=150 c_co_dim=0 c_ic_enc_dim=64 c_gen_dim=64 c_factors_dim=8 spikeBinMs: 2 c_allow_gpu_growth: true c_max_ckpt_to_keep: 5 c_max_ckpt_to_keep_lve: 5 c_device: /gpu:0 c_learning_rate_init: 0.01 c_learning_rate_decay_factor: 0.98 c_learning_rate_n_to_compare: 6 c_learning_rate_stop: 0.001 c_max_grad_norm: 200 trainToTestRatio: 4 c_batch_size: 150 c_cell_clip_value: 5 c_temporal_spike_jitter_width: 0 c_keep_prob: 0.95 c_l2_gen_scale: 500 c_l2_con_scale: 500 c_co_mean_corr_scale: 0 c_kl_ic_weight: 1 c_kl_co_weight: 1 c_kl_start_step: 0 c_kl_increase_steps: 900 c_l2_start_step: 0 c_l2_increase_steps: 900 scaleIncreaseStepsWithDatasets: true c_ext_input_dim: 0 c_inject_ext_input_to_gen: false c_co_dim: 0 c_prior_ar_atau: 10 c_do_train_prior_ar_atau: true c_prior_ar_nvar: 0.1 c_do_train_prior_ar_nvar: true c_do_causal_controller: false c_do_feed_factors_to_controller: true c_feedback_factors_or_rates: factors c_controller_input_lag: 1 c_ci_enc_dim: 128 c_con_dim: 128 c_co_prior_var_scale: 0.1 c_num_steps_for_gen_ic: 4294967295 c_ic_dim: 64 c_ic_enc_dim: 64 c_ic_prior_var_min: 0.1 c_ic_prior_var_scale: 0.1 c_ic_prior_var_max: 0.1 c_ic_post_var_min: 0.0001 c_cell_weight_scale: 1 c_gen_dim: 64 c_gen_cell_input_weight_scale: 1 c_gen_cell_rec_weight_scale: 1 c_factors_dim: 8 c_output_dist: poisson c_do_train_readin: true useAlignmentMatrix: false useSingleDatasetAlignmentMatrix: false posterior_mean_kind: posterior_sample_and_average num_samples_posterior: 512